- Published on
Google Benchmark
- Authors

- Name
- Ramtin Tajbakhsh
- What is Google Benchmark
- Setting Up with CMake
- Examples
- Limitations of Microbenchmarking
- References and Further Reading
What is Google Benchmark
Google Benchmark is a library that's developed and maintained by Google and it allows us to measure the runtime performance of our code with impressive accuracy. You might wonder, "Why bother with a library when I can just write my own manual benchmarks?" That's a fair question. To answer it, let's compare a manual benchmark and one using Google Benchmark by measuring the performance of std::sort. This will give us a clearer picture of why using Google Benchmark is often the better choice.
Here is the manual version:
#include <iostream>
#include <chrono>
#include <vector>
#include <algorithm>
#include <random>
std::vector<int> generate_random_array(size_t size) {
std::vector<int> arr(size);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dist(1, 1000000);
for (auto& num: arr) {
num = dist(gen);
}
return array;
}
void BenchmarkSort(size_t array_size, int iterations) {
double total_time = 0.0;
for (int i = 0; i < iterations; ++i) {
auto array = generate_random_array(array_size);
auto start = std::chrono::high_resolution_clock::now();
std::sort(array.begin(), array.end());
auto end = std::chrono::high_resolution_clock::now();
total_time += std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}
double avg_time = total_time / iterations;
std::cout << "Average time: " << avg_time << " microseconds";
}
int main() {
const size_t array_size = 100000;
const int iterations = 100; // We can adjust this as needed
BenchmarkSort(array_size, iterations);
return 0;
}
This approach works if we only care about the average run time of a certain function, but it has its limitations. Here are some that I can think of:
- There is a lot of boilerplate code to handle timing, managing iterations, and formatting the result
- If we want to run the same benchmark on different input sizes, we will have to write even more boilerplate code
- The result generated from the benchmark above doesn't have much statistical significance because we are hardcoding the number of iterations instead of dynamically adjusting it to ensure the result is stable.
- This benchmark doesn't tell us anything about complexity scaling or memory usage of the function. Now let's run the same benchmark using Google Benchmark:
#include <benchmark/benchmark.h>
#include <vector>
#include <algorithm>
#include <random>
std::vector<int> generate_random_array(size_t size) {
std::vector<int> arr(size);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dist(1, 1000000);
for (auto& num: arr) {
num = dist(gen);
}
return array;
}
static void BM_SortArray(benchmark::State& state) {
const size_t array_size = state.range(0);
for (auto _ : state) {
auto array = generate_random_array(array_size);
std::sort(array.begin(), array.end());
}
}
BENCHMARK(BM_SortArray)->Arg(1000)->Arg(10000)->Arg(100000);
BENCHMARK_MAIN();
This is already a lot cleaner and more readable. But it's not just about readability, here are some of the other benefits of this approach:
- It's very easy to scale and benchmark the function using a variety of input sizes
- There will be much less noise, as Google Benchmark will dynamically adjust the number of iterations until the result is statistically stable, and it automatically discards the outliers
- Google Benchmark has a lot of other cool features and I'll discuss some in the rest of this article
Setting Up with CMake
If you have CMake 3.14+, you can use FetchContent to easily download and use the Google Benchmark library. An example CMakeLists.txt file:
cmake_minimum_required(VERSION 3.14)
project(g_bench)
enable_testing()
include(FetchContent)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED YES)
set(CMAKE_CXX_EXTENSIONS NO)
FetchContent_Declare(googletest
GIT_REPOSITORY https://github.com/google/googletest.git
GIT_TAG v1.14.0)
FetchContent_Declare(googlebenchmark
GIT_REPOSITORY https://github.com/google/benchmark.git
GIT_TAG main)
FetchContent_MakeAvailable(
googletest
googlebenchmark
)
add_executable(${PROJECT_NAME} main.cpp)
target_link_libraries(${PROJECT_NAME} benchmark::benchmark)
To get started quickly, you can clone and use this template from my GitHub: Google Benchmark Boilerplate.
Examples
For the following examples, the screenshots are taken on my machine with the following specs:
- CPU: Intel Core i9-13900K, 24 Cores (8 P-cores + 16 E-cores) base 3GHz, up to 5.8GHz
- RAM: 32GB DDR5 @ 7200MHz
- OS: Ubuntu 22.04.5 LTS
- Compiler: GCC 11.4.0
Anatomy of a Simple Benchmark
each microbenchmark is a function that takes a parameter of type benchmark::State&. We can pass arguments to our benchmark function through this parameter. For each benchmark function, we should register it using the BENCHMARK macro. All the functions and data types for Google Benchmark are in <benchmark/benchmark.h> header file. Here is a very basic example:
#include <benchmark/benchmark.h>
static void BM_SimpleLoop(benchmark::State& state) {
for (auto _ : state) { // Iterations
int x = 0; // Code inside the loop will be benchmarked
for (int i = 0; i < 1000; ++i) {
x += i;
}
}
}
// Register the benchmark function
BENCHMARK(BM_SimpleLoop);
// macro that expands into main function
BENCHMARK_MAIN();
This is result of the benchmark:

Another neat feature of Google Benchmark is that we don't need to manually write a main function and the BENCHMARK_MAIN macro takes care of that. For those who want to know what BENCHMARK_MAIN expands into, here is the source code: BENCHMARK_MAIN Macro
Another thing to keep in mind regarding the code example above, is that there is a high chance the entire for loop will be optimized away by the compiler since the variable x is not used at all after the for loop and modern compilers are smart enough to notice that. So it's obviously not a good benchmark but it's just to demonstrate the anatomy of simple benchmarks.
Passing Argument (Input Size)
We can also pass arguments to our benchmark function to compare the result with various input sizes using BENCHMARK(bench_name)->Args(...). Here is an example:
#include <benchmark/benchmark.h>
#include <vector>
static void BM_VectorPushBack(benchmark::State& state) {
for (auto _ : state) {
std::vector<int> v;
for (int i = 0; i < state.range(0); ++i) {
v.push_back(i);
}
}
}
// Pass input size
BENCHMARK(BM_VectorPushBack)->Arg(1000)->Arg(10000)->Arg(100000);
BENCHMARK_MAIN();
This will run the same benchmark with vectors of sizes 1000, 10000, 100000. Here is a screenshot of the result:

We can use Range and RangeMultiplier to achieve the exact same thing as above:
BENCHMARK(BM_VectorPushBack)->RangeMultiplier(10)->Range(1000, 100000);
There are a lot of other cool ways to pass values to our benchmark functions such as DenseRange, Ranges, and ArgsProduct. I don't want to make this blog post too long, you can read about all of these in the User Guide
Finding the Time Complexity
Something that blew me away, is that Google Benchmark allows us to estimate the BigO time complexity of our benchmark functions as well. For instance, we can find the time complexity of std::sort this way:
#include <benchmark/benchmark.h>
#include <algorithm>
#include <vector>
static void BM_SortComplexity(benchmark::State& state) {
std::vector<int> data(state.range(0));
for (auto& x: data) x = rand();
for (auto _: state) {
std::sort(data.begin(), data.end());
}
state.SetComplexityN(state.range(0));
}
BENCHMARK(BM_SortComplexity)
->RangeMultiplier(2)
->Range(1 << 10, 1 << 20)
->Complexity();
BENCHMARK_MAIN();
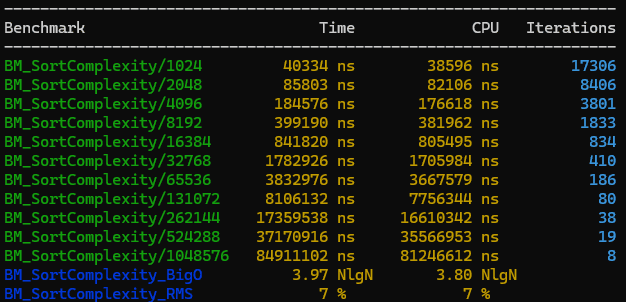
Limitations of Microbenchmarking
Microbenchmarking is great. It let's us quickly measure the performance of some piece of code, make small changes and see their effects, and find bottlenecks of our code. But like everything else in Software Engineering, there are tradeoffs. Here are some of the limitations of microbenchmarking:
Over-optimization and Code Readability
Microbenchmarking makes it very tempting to spend a lot of time and over-optimize the code. Since microbenchmarking makes it easy to see the impact of small changes, we may end up making a lot of small random changes to squeeze the last bit of performance from our code. But this comes at the cost of maintainability and readability of our code for future developers (and ourselves).
Inconsistent Results
We might get vastly different results depending on where we run our code. Different hardware, operating system, compiler, workload of other processes, and a lot of other factors can heavily affect the result of these benchmarks.
Isolation
Microbenchmarking only gives us insight about the performance of some piece of code in isolation and it doesn't take the full context of our application into account. The effects of things like disk I/O, OS interrupts, frequent context switches, and many other things are not reflected in microbenchmarks.
Despite all these limitations, I still think microbenchmarking is great :)
References and Further Reading
The User Guide of Google Benchmark is very comprehensive and easy to follow and I learned pretty much everything about Google Benchmark by reading it. I highly recommend it.
Some other resources to look into:
- The Art of Writing Efficient Programs has a lot of examples using Google Benchmark. Chapters 2 and 3 specifically, introduce the library and its usage
- Chandler Carruth talks at CppCon are extremely insightful for anyone who is interested in C++ and optimization. Chandler Carruth leads the C++, Clang, and LLVM teams at Google and his main focus is optimization.